Understanding PostgreSQL Index Types
Apr 26, 2024 by Robert Gravelle
PostgreSQL, the popular open-source relational database management system, offers various index types to optimize query performance and enhance data retrieval efficiency. In this article, we’ll learn how to create different types of indexes in PostgreSQL. Wherever possible, indexes will be applied to the free “dvdrental” sample database using both DML statements as well as Navicat for PostgreSQL 16.
The B-Tree index is the default index type in PostgreSQL, suitable for various data types, including text, numeric, and timestamp. It organizes data in a balanced tree structure, facilitating efficient range queries and equality searches. Let’s create a B-Tree index on the “customer_id” column in the “payment” table:
CREATE INDEX btree_customer_id_idx ON payment(customer_id);
In Navicat you’ll find indexes on the “Indexes” tab of the Table Designer. To create the above index, we would enter “btree_customer_id_idx” in the Name field, choose “customer_id” for the “Fields”, and select “B-Tree” from the Index method drop-down:
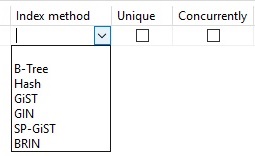
Here is the btree_customer_id_idx index with all of the above fields populated:
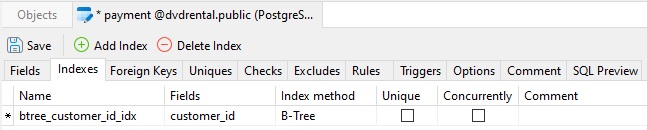
Clicking the Save button with then create the index.
Hash indexes are optimal for equality checks but less effective for range queries. They use hash functions to map keys to index entries. Here’s how to create a Hash index on the “film_id” column of the “inventory” table, first using a DML statement:
CREATE INDEX hash_film_id_idx ON inventory USING HASH(film_id);
And now with Navicat:

Generalized Search Tree (GiST) indexes support various data types and complex queries, making them versatile for applications like full-text search and geometric data types.
Here’s an example of creating a GiST index on a geometry column:
CREATE INDEX index_geometry ON table_name USING GIST (geometry_column);
Space-Partitioned Generalized Search Tree (SP-GiST) indexes are suitable for data types with multidimensional or hierarchical structures. They efficiently index non-balanced trees.
Here’s an example of creating an SP-GiST index on a tsvector column:
CREATE INDEX index_text_search ON table_name USING SPGIST (tsvector_column);
Generalized Inverted Index (GIN) is ideal for cases like full-text search, array types, and composite data types. They are efficient for data types with multiple keys or components. Let’s create a GIN index on the “title” column in the “film” table for full-text search:
CREATE INDEX gin_title_idx ON film USING gin(to_tsvector('english', title));
Here is the Indexes tab of the “film” table in Navicat with the gin_title_idx index added:

Block Range Index (BRIN) is suitable for large tables with sorted data, as it indexes ranges of data blocks rather than individual rows. It is efficient for columns with correlation between adjacent values. Here’s how to create a BRIN index on the “rental_date” column in the “rental” table:
CREATE INDEX brin_rental_date_idx ON rental USING brin(rental_date);
Here is the brin_rental_date_idx index in Navicat:

PostgreSQL offers a range of index types catering to diverse data types and query requirements. Understanding the characteristics of each index type helps database administrators and developers to make informed decisions when optimizing database performance. Meanwhile, using a tool like Navicat for PostgreSQL 16 makes working with indexes much easier.