
Choosing a Primary Key – Part 1
Choosing a Primary Key – Part 1
Aug 12, 2022 by Robert Gravelle
One of the first decisions you’ll be faced with as a database designer is what kind of Primary Key (PK) to use on your tables. If you ask anyone who works with databases on a daily basis, whether database administrator, developer, or tester, you’ll get a myriad of opinions and justifications to go along with them. Compounding the impediments to coming up with an answer is that there is no one size fits all solution. With that in mind, this series will present some reasons both for and against different types of PKs. Somewhere in all those ideas, there will be a few that will steer you towards the best type of PK to use for your organizational needs. In this first instalment, we’ll compare the two basic types of PKs: Natural and Surrogate Keys. Later, we’ll cover the questions of whether or not to use the database Auto Increment feature as well as which data type(s) – if any – make the best PKs.
A natural key is one made up of one or more columns that already exist in the table (e.g. they are attributes of the entity within the data model) that uniquely identify a record in the table. Since these columns are attributes of the entity they inherently possess business meaning. The following is an example of a table with a natural key in Navicat Premium 16‘s Table Designer. We can easily identify the Primary Key by the key icon in the Key column:
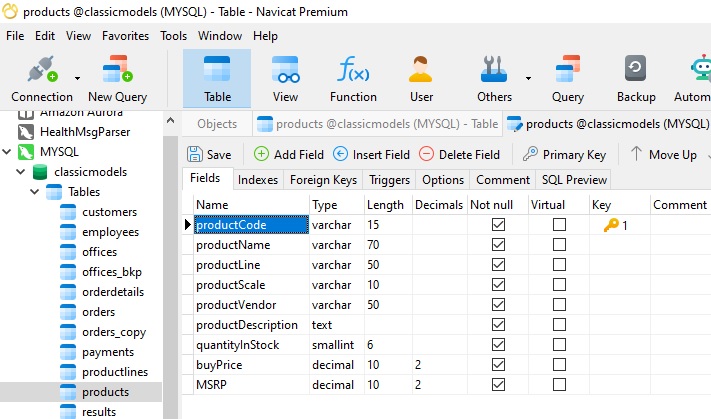
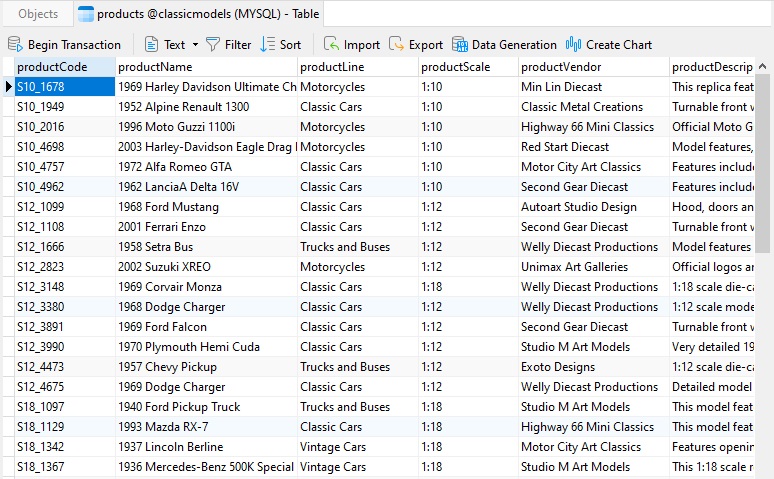
Looking at the data, we can see that the productCode has business meaning:
A surrogate key (or synthetic key, pseudokey, entity identifier, factless key, technical key, etc!) is a system generated (GUID, sequence, unique identifier, etc.) value with no business meaning that is used to uniquely identify a record in a table. The key itself could be made up of one or multiple columns (i.e. Composite Key) as well. We can see a surrogate key in a table from the same database, which defines a customerNumber column as its PK:
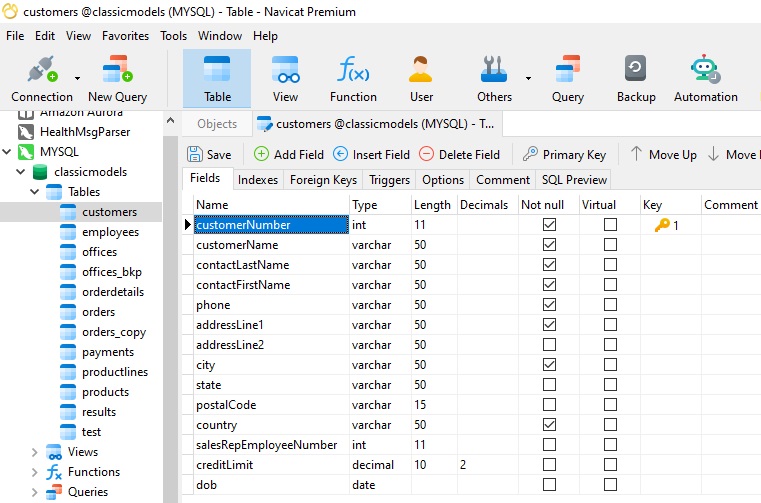
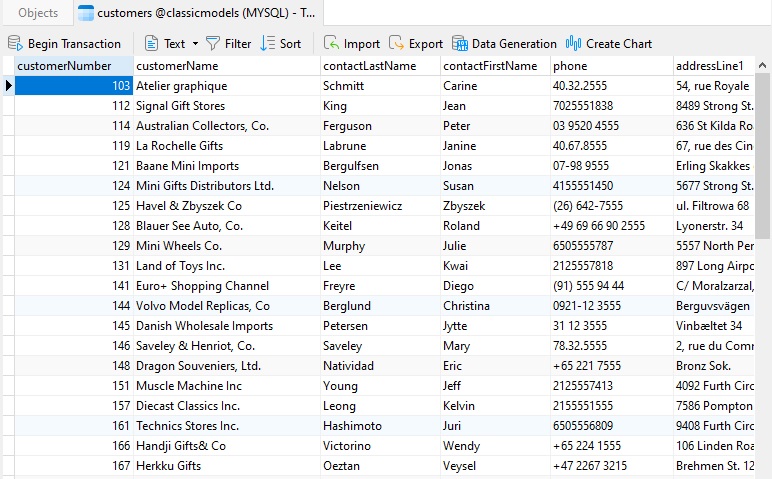
Although not Auto Incrementing, it’s a numeric field that is unrelated to the customer entity:
So why does one table employ a Natural Key while the other utilizes a Surrogate Key?
It’s quite common for products to have some sort of unique inventory number, which makes an ideal PK. Adding an additional numeric key would simply be a waste of disk space and would almost certainly require an additional index on the productCode column for searching. On the other hand, customers don’t typically come with unique identifiers. Speaking as someone who has had to uniquely identify persons in a database, it takes a surprisingly long list of columns to do so. Hence, it’s usually much easier to assign a numeric Surrogate Key that index every column in the table.
In this first instalment on Choosing a Primary Key, we explored Natural and Surrogate Primary Keys and considered why one might choose one over the other. It’s important to decide between using a Natural or Surrogate first because which you choose will help answer some of the follow-up questions as well – especially in the case of a surrogate key.
If you’d like to give Navicat 16 a test drive, you can download a 14 day trial here.
