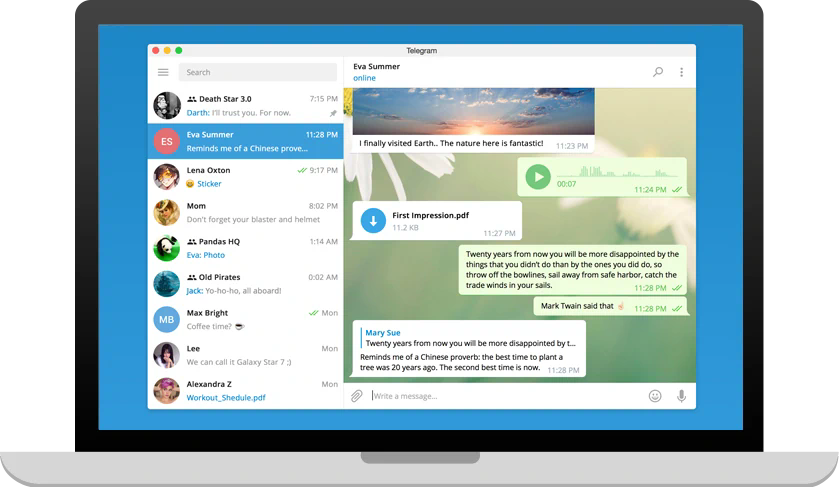
Telegram 是一款基于云的移动和桌面消息传递应用程序,专注于安全性和速度。
Telegram 非常简单,您已经知道如何使用它。
Telegram 消息经过高度加密,可以自毁。
Telegram 允许您从多个设备访问您的聊天。
Telegram 发送消息的速度比任何其他应用程序都快。
Telegram 有一个开放的 API 和源代码,对每个人都是免费的。
Telegram 保护您的消息免受黑客攻击。
Telegram 群组最多可容纳 200,000 名成员。
Telegram 可让您完全自定义您的信使。
Telegram中文版常见问题解答,获取关于Telegram中文版使用、功能设置、隐私保护和故障排查的详细指南。无论您是新用户还是老用户,这里都有您需要的信息。